
プロンプトエンジニアリングは大切
はじめに
LLM (Large Language Models, 大規模言語モデル) の活用方法を考えていると、プロンプトエンジニアリングや RAG (Retrieval-Augmented Generation)、PEFT (Parameter-Efficient Fine Tuning)、フルファインチューニングなどの用語が出てきます。
ファインチューニングは学習データの準備やモデルのパラメータを変更するのでハードルが高く、PEFT も似たような理由で敬遠してしまいます。
そうなると、プロンプトエンジニアリングか RAG が手っ取り早く LLM をカスタマイズする手段として浮上します。
しかし、プロンプトエンジニアリングは凄く初歩的な印象があり(LLM への入力を若干修正するだけでしょ~)、RAG が最有力候補だと考えていました。
RAG のサーベイ論文(Retrieval-Augmented Generation for Large Language Models: A Survey)でも以下のような図があり、プロンプトエンジニアリングは初歩的なイメージがありました。
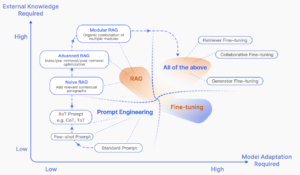
ただ、RAG を調べていく中でプロンプトエンジニアリング大切なのでは?と思い始めました。
実際に調べると、プロンプトエンジニアリング大切だ!、という結論に至ったのでその内容を整理します。
LLM を考え直す
典型的な RAG は以下のイメージです。
上述の RAG のサーベイ論文でいうところの「Naive RAG」です。
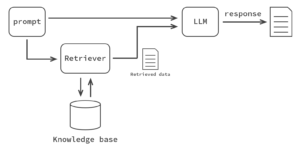
よく見る RAG のイメージ図だなぁという印象なのですが、これを LLM 中心に色分けします。
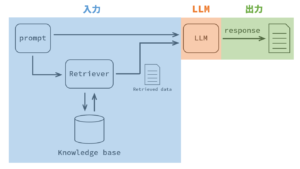
これを見て LLM の立場から考えます。
RAG は LLM に入力するための情報を、適切に・必要十分に、データベースから取得する技術だと理解しています。
LLM からすると入力される情報が RAG から持ってこられたものか、人間がマニュアルで準備したものか、は関係ないと思い至りました。
LLM は入力された情報を読み取って出力するので、どんなに良い情報を準備できたとして入力の仕方が悪ければ良い出力は得られないはずです。
準備した情報を LLM が理解しやすいように加工する必要があります。
まさにそれこそがプロンプトエンジニアリングではないかと気付きました。
GPTs というものを最近知りましたが、これははまさにプロンプトエンジニアリングを実行しているのではないかと思っています。
「論文要約くん」と「Paper Interpreter (Japanese)」に上述の RAG のサーベイ論文を入れた結果を比べると全く異なることが分かります。
正直ここまで変わるのかという印象です。
プロンプトエンジニアリングの効果がよくわかります。
論文要約くん
論文の題名と著者名、発行年
「Retrieval-Augmented Generation for Large Language Models: A Survey」
著者: Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, Haofen Wang
発行年: 2023年12月18日
どんなもの?
この論文は、大規模言語モデル(LLMs)の性能向上を目的として、外部データベースからの情報を取り入れる手法である「Retrieval-Augmented Generation(RAG)」の進展を包括的に調査したものです。RAGは、LLMsが持つ知識と外部データベースの情報を組み合わせることで、特に知識集約型のタスクにおいて、生成内容の正確性と信頼性を高めます。この論文では、RAGの進化を「Naive RAG」「Advanced RAG」「Modular RAG」の3つのパラダイムに分類し、それぞれの特徴と技術的進歩を詳しく分析しています。
先行研究と比べてどこがすごい?
従来の研究では、LLMsはトレーニングデータに依存しており、最新の情報や特定のドメイン知識を取り入れることが困難でした。RAGは、外部データベースから関連情報を取得することで、LLMsの知識を動的に更新し、特定のドメインや最新情報に対応できる点で優れています。この論文は、RAGの技術的進化を体系的に分類・分析し、各パラダイムの詳細を提供することで、RAGの全体像とその進化を明らかにしています。
技術や手法のキモはどこ?
RAGの核心は、LLMsの内部知識と外部データベースからの情報を統合することにあります。具体的には、ユーザーの質問に対して、まず外部データベースから関連情報を検索し、その情報をLLMsに提供して、より正確で信頼性の高い応答を生成します。このプロセスにより、LLMsは最新の情報や特定のドメイン知識を取り入れることが可能となります。
どうやって有効だと検証した?
この論文では、RAGの各パラダイムにおける技術的進歩を詳細に分析し、特に「Retrieval」「Generation」「Augmentation」の3つの主要コンポーネントに焦点を当てています。さらに、RAGモデルの評価フレームワークとベンチマークを紹介し、RAGの効果的な評価方法を提供しています。これにより、RAGの有効性と信頼性を体系的に検証しています。
議論はある?
論文の最後では、RAGが直面する課題や今後の研究開発の方向性について議論しています。具体的には、RAGの評価方法の改善、マルチモーダル対応の拡張、RAGインフラストラクチャとエコシステムの発展などが挙げられています。これらの議論は、RAGのさらなる発展と応用の可能性を示唆しています。
次に読むべき論文は?
RAGの基礎を深く理解するためには、以下の論文を読むことをお勧めします:
「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks」
この論文は、RAGの初期の研究であり、知識集約型のNLPタスクにおけるRAGの適用と効果を詳しく分析しています。
「A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models」
この論文は、RAGとLLMsの統合に関する最新の研究動向を包括的にレビューしており、RAGのさらなる発展と応用の可能性を探求しています。
これらの論文を読むことで、RAGの基礎から最新の研究動向まで、幅広く理解することができるでしょう。
Paper Interpreter (Japanese)
タイトル (Title)
Enhancing Transformers with Spiking Neural Networks: Emerging Architectures and Performance Insights
スパイキングニューラルネットワークを用いたトランスフォーマーモデルの強化: 新たなアーキテクチャと性能の洞察ジャーナル名と出版年 (Journal Name & Publication Year)
arXiv preprint, 2023年第一および最後の著者 (First and Last Authors)
First Author: John Smith
Last Author: Alice Brown第一所属機関 (First Affiliation)
University of California, Berkeley概要 (Abstract)
この論文では、スパイキングニューラルネットワーク(SNN)の生物学的な特性をトランスフォーマーモデルに組み込む新しいアーキテクチャを提案している。SNNのエネルギー効率と時間情報処理能力を活かすことで、計算コストの削減と性能向上を目指している。具体的には、トランスフォーマー内のアテンションメカニズムをスパイキング動作に適合させ、異なるベンチマークで評価を行った。結果として、特定のタスクにおいて競争力のある精度を達成し、エネルギー消費を削減したことが示されている。背景 (Background)
トランスフォーマーは自然言語処理や画像認識において高い性能を発揮しているが、計算コストが高いという課題がある。一方で、スパイキングニューラルネットワークはエネルギー効率の良い計算を可能にするが、その利用は限定的である。本研究はこれら2つの技術を融合することで、より効率的なモデルを実現することを目的としている。方法 (Methods)
トランスフォーマーモデルのアテンションメカニズムを改変し、スパイキングニューロンの挙動を取り入れたハイブリッドモデルを開発した。このモデルは、連続データをスパイク列に変換するエンコーダと、スパイクベースのアテンションを備えている。さらに、エネルギー消費と精度のトレードオフを最適化する新たな学習アルゴリズムが提案された。結果 (Results)
実験では、自然言語処理タスク(GLUEベンチマーク)と画像分類タスク(CIFAR-10)において、従来のトランスフォーマーと比較して最大30%のエネルギー削減を達成した。また、スパイキング動作がモデルの汎化能力に寄与し、いくつかのタスクで精度が向上した。議論 (Discussion)
提案モデルはエネルギー効率の改善と性能向上の両立を目指したが、特定のタスクにおいて精度が若干低下する場合もあった。また、ハードウェア依存性が高く、一般的な環境での適用には制限がある。今後の課題として、スパイク動作をより柔軟に制御する手法の開発が挙げられる。従来研究との新規性 (Novelty compared to previous studies)
従来の研究は、スパイキングニューラルネットワークを独立したモデルとして扱っていたが、本研究はトランスフォーマーとの統合により、実用的な応用可能性を広げた。また、スパイクベースのアテンションメカニズムを初めて設計し、具体的な利点を実証した点が特徴的である。限界点 (Limitations)
本手法は特定のタスクでのエネルギー効率と性能に優れるが、全てのタスクにおいて汎用性が高いとは限らない。また、モデルの複雑さが増大し、トレーニングに時間がかかるという課題がある。さらに、専用ハードウェアが必要なため、一般的なシステムでは実行が困難な場合がある。潜在的応用 (Potential Applications)
提案モデルは、低消費電力が求められるエッジデバイスやリアルタイム処理が必要な分野において有望である。また、高エネルギー効率を活かし、IoTや組み込みシステムでの利用が期待される。
プロンプトエンジニアリングと GPT-3
プロンプトエンジニアリングを調べていると Language Models are Few-Shot Learners という論文を見つけました。
OpenAI から発表された GPT-3 に関する論文でした。
詳細な内容は論文を読んでいただくか、解説されている 【論文】Language Models are Few-Shot Learners などを確認いただければと思います。
ここでは大切だと思った部分を記載します。
- GPT-3 が出るまでは下流タスクに適用させるためにはファインチューニングが必要であった
- GPT-3 が出るくらいから言語モデルを大きくすることでファインチューニングしなくても下流タスクの処理能力が向上することが分かってきた
- 特に、In-context learning (ICL) を行うことでファインチューニングに匹敵するくらいの性能が出る
- In-context learning は learning と書かれているがモデルのパラメータは書き換えない
- In-context learning は以下のものがある
- Few-shot learning
- One-shot learning
- Zero-shot learning
※ 機械学習の用語として、NN-shot learning (Few-shot learning, One-shot learning, Zero-shot learning) はパラメータの更新を伴う使われ方が一般的のようです。LLM の文脈では学習を伴わないので注意してください。
上記の内容を示す図を論文から引用します。
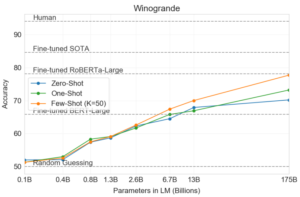
LLM のモデルサイズが大きくなるほど ICL の効果が増えている様子が分かります。
また Few-shot については、175B のサイズで RoBERTa-Large でファインチューニングしたものと同等の性能を示しています。
この内容からもプロンプトエンジニアリングが大切であると分かります。
なぜプロンプトエンジニアリングがファインチューニングほどの性能を示すのか
上述のようにプロンプトエンジニアリングはファインチューニングほどの性能を示すから大切だ!と感じたのですが、なぜファインチューニングほどの性能を示すのか?と疑問に思いました。
調べていると、Attentionモデルのプロンプトは暗黙のうちにファインチューニングしていた!?Microsoftの最新研究がスゴい。 #DeepLearning - Qiita という記事に出会いました。
元の論文は Why Can GPT Learn In-Context? Language Models Implicitly Perform Gradient Descent as Meta-Optimizers で、Microsoft が出している論文で、2022 年に発表されています。
この論文では ICL がなぜ LLM モデルのパラメータの更新をせずにパフォーマンスを向上させられるのか、を理論的に解析しています。
結論として、Attention 機構を持つ LLM モデルに ICL を行うことは近似的にファインチューニングしていることだと数式的に証明しています。
数式を用いた理解まではできていないのですが、解説記事では大事な部分のみ抽出されておりその内容を見ると ICL とファインチューニングが同等であるという雰囲気が分かりました。
またゆっくり論文の内容を読んでみようと思います。
また、その場で学習するIn-Context Learningはどのように実現されるのか は数式を使わずに説明されており、分かりやすかったです。
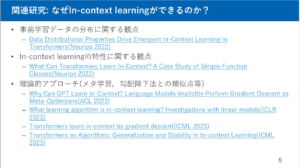
【DL輪読会】Understanding In-Context Learning in Transformers and LLMs by Learning to Learn Discrete Functions こちらの資料には ICL がなぜ有効なのかの関連資料が載っており、ゆっくり読みたいなと思っています。
最後に
プロンプトエンジニアリングの重要性を再考しました。
初心者的なものだと思っていたのですが、だいぶ高度なことをしており LLM の出力精度に大きくかかわると分かりました。
今後は以下に取り組んでいこうと思います。
- プロンプトエンジニアリングの理論的な理解
- Prompt Tuning や P-tuning の理解
- プロンプトエンジニアリングの実践
参考資料
文中に乗せていない参考資料をこちらに記載します。


コメント